- 需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
- 环境准备
(1)在hadoop104主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称
(3)删除原来HDFS文件系统留存的文件(/opt/module/hadoop-2.7.2/data和log)
(4)source一下配置文件
[atguigu@hadoop105 hadoop-2.7.2]$ source /etc/profile
- 服役新节点具体步骤
(1)直接启动DataNode,即可关联到集群
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
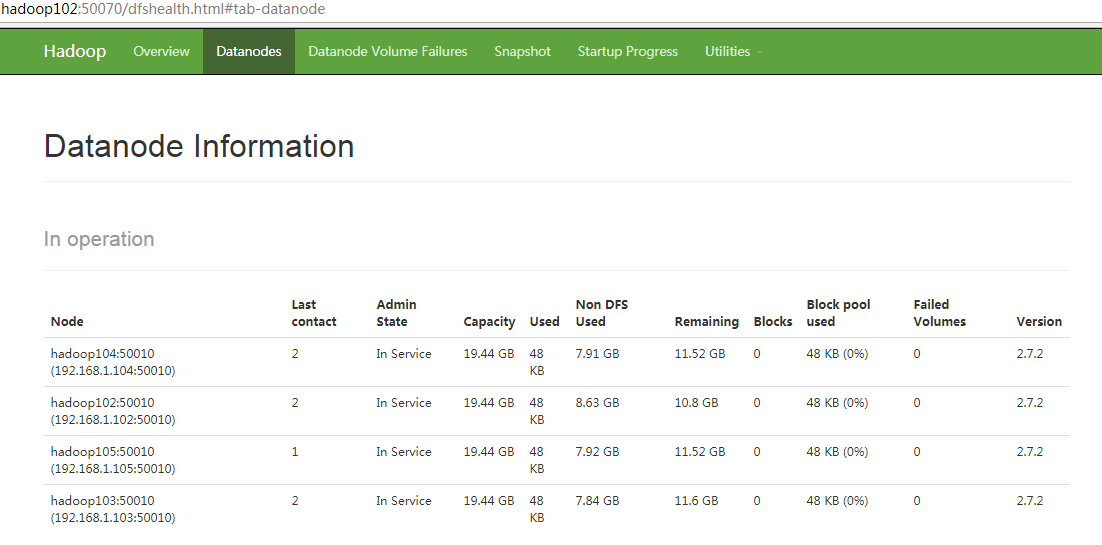
(2)在hadoop105上上传文件
[atguigu@hadoop105 hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt /
(3)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习
上一篇: Java培训课程在Eclipse中安装SVN客户端插件之检出
下一篇: 大数据培训之退役旧数据节点
