1、where条件查询
从原表中的记录中进行筛选
2、group by 分组查询
很多情况下,用户都需要进行一些汇总操作,比如统计整个公司的人数或者统计每一个部门的人数等。
聚合函数
- AVG(【DISTINCT】 expr) 返回expr的平均值
- COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目
- MIN(【DISTINCT】 expr)返回expr的最小值
- MAX(【DISTINCT】 expr)返回expr的最大值
- SUM(【DISTINCT】 expr)返回expr的总和
|
#聚合函数 #AVG(【DISTINCT】 expr) 返回expr的平均值 SELECT AVG(basic_salary) FROM t_salary;
#COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目 #统计员工总人数 SELECT COUNT(*) FROM t_employee;#count(*)统计的是记录数 #统计员工表的员工所在部门数 SELECT COUNT(dept_id) FROM t_employee;#统计的是非NULL值 SELECT COUNT(DISTINCT dept_id) FROM t_employee;#统计的是非NULL值,并且去重
#MIN(【DISTINCT】 expr)返回expr的最小值 #查询最低基本工资值 SELECT MIN(basic_salary) FROM t_salary;
#MAX(【DISTINCT】 expr)返回expr的最大值 #查询最高基本工资值 SELECT MAX(basic_salary) FROM t_salary;
#查询最高基本工资与最低基本工资的差值 SELECT MAX(basic_salary)-MIN(basic_salary) FROM t_salary;
#SUM(【DISTINCT】 expr)返回expr的总和 #查询基本工资总和 SELECT SUM(basic_salary) FROM t_salary; |
group by + 聚合函数
|
#group by + 聚合函数 #统计每个部门的人数 SELECT dept_id,COUNT(*) FROM t_employee GROUP BY dept_id;
#统计每个部门的平均基本工资 SELECT emp.dept_id,AVG(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id;
#统计每个部门的年龄最大者 SELECT dept_id,MIN(birthday) FROM t_employee GROUP BY dept_id;
#统计每个部门基本工资最高者 SELECT emp.dept_id,MAX(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id;
#统计每个部门基本工资之和 SELECT emp.dept_id,SUM(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id; |
注意:
用count(*),count(1),谁好呢?
其实,对于myisam引擎的表,没有区别的.
这种引擎内部有一计数器在维护着行数.
Innodb的表,用count(*)直接读行数,效率很低,因为innodb真的要去数一遍.
关于mysql的group by的特殊:
注意:在SELECT 列表中所有未包含在组函数中的列都应该是包含在 GROUP BY 子句中的,换句话说,SELECT列表中最好不要出现GROUP BY子句中没有的列。
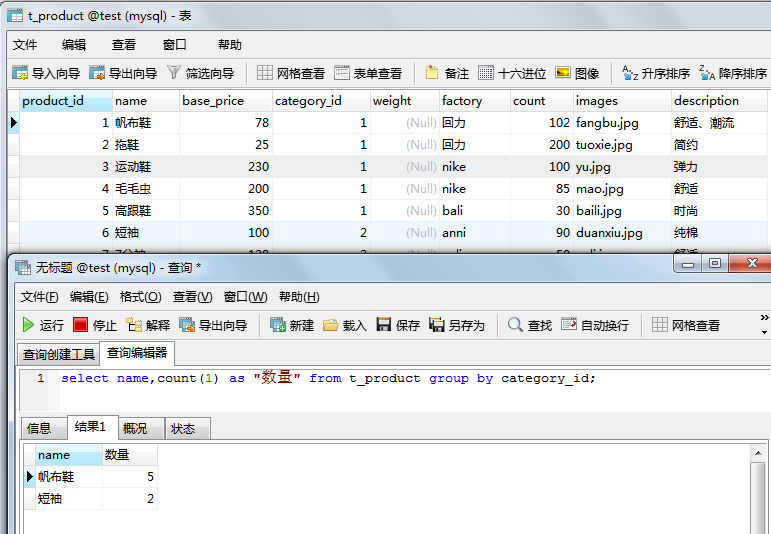
对于标准语句来说,这个语句是错误的,但是mysql可以这么干,出于可移植性和规范性,不推荐这么写。
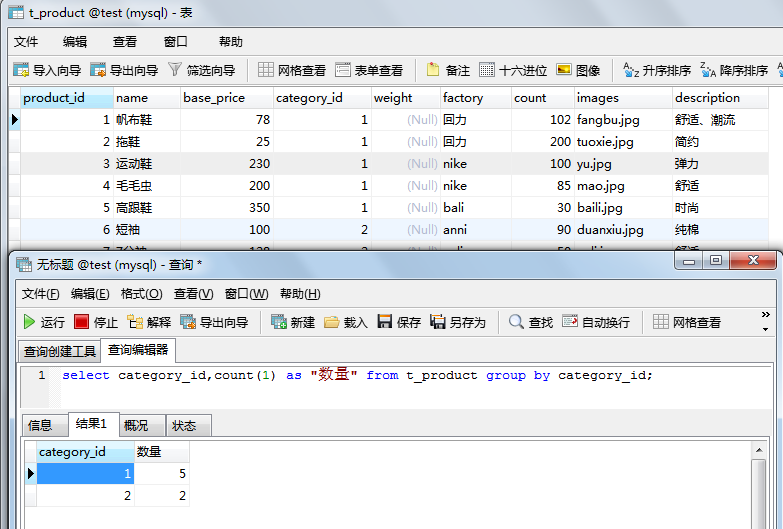
3、having 筛选
having与where类似,可筛选数据
having与where不同点
- where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据
- where后面不能写分组函数,而having后面可以使用分组函数
- having只用于group by分组统计语句
|
#按照部门统计员工人数,仅显示部门人数少于3人的 SELECT dept_id,COUNT(*) AS c FROM t_employee WHERE dept_id IS NOT NULL GROUP BY dept_id HAVING c <3; |
|
#查询每个部门的平均工资,并且仅显示平均工资高于10000 SELECT emp.dept_id,AVG(s.basic_salary ) AS avg_salary FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid AND dept_id IS NOT NULL GROUP BY emp.dept_id HAVING avg_salary >10000; |
4、order by 排序
- 按一个或多个字段对查询结果进行排序
用法:order by col1,col2,col3…
说明:先按col1排序如果col1相同就按照col2排序,依次类推
col1,col2,col3可以是select后面的字段也可以不是
- 默认是升序,也可以在字段后面加asc显示说明是升序,desc为降序
例如:order by click_count desc;
如果两个字段排序不一样,例如:
order by 字段1 asc ,字段2 desc;
- order by 后面除了跟1个或多个字段,还可以写表达式,函数,别名等
|
#排序 #查询员工基本工资,按照基本工资升序排列,如果工资相同,按照eid升序排列 SELECT t_employee.eid,basic_salary FROM t_employee INNER JOIN t_salary ON t_employee.eid = t_salary.eid ORDER BY basic_salary,eid;
#查询员工基本工资,按照基本工资降序排列,如果工资相同,按照eid排列 SELECT t_employee.eid,basic_salary FROM t_employee INNER JOIN t_salary ON t_employee.eid = t_salary.eid ORDER BY basic_salary DESC,eid;
#统计每个部门的平均基本工资,并按照平均工资降序排列 SELECT emp.dept_id,AVG(s.basic_salary) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id ORDER BY AVG(s.basic_salary) DESC; |
5、limit 分页
limit m,n
m表示从下标为m的记录开始查询,第一条记录下标为0,n表示取出n条出来,如果从m开始不够n条了,就有几条取几条。m=(page-1)*n,(page页码,n表示每页显示的条数)
如果第一页limit 0,n
如果第二页limit n,n
依次类推,得出公式limit (page-1)*n , n
|
#分页 #查询员工信息,每页显示5条,第二页 SELECT * FROM t_employee LIMIT 5,5;
#统计每个部门的平均基本工资,并显示前三名 SELECT emp.dept_id,AVG(s.basic_salary) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id ORDER BY AVG(s.basic_salary) DESC LIMIT 0,3; |
上一篇: java培训课程之关联查询
下一篇: Java培训课程之子查询
